%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# computer vision
Diffusion Vas
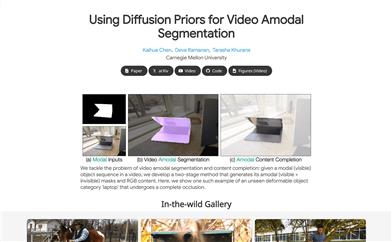
This model for non-visible object segmentation and content completion in videos was proposed by Carnegie Mellon University. It processes sequences of visible objects in a video using a conditional generation approach, leveraging foundational knowledge from video generation models to produce masks and RGB content that include both visible and occluded parts. The main advantages of this technology include its ability to effectively handle highly occluded situations and deformable objects. Additionally, the model outperforms existing state-of-the-art methods across multiple datasets, showing up to a 13% performance improvement in the segmentation of non-visible areas obstructed by objects.
Video Production
45.0K
Vggsfm
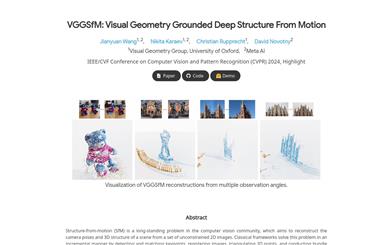
VGGSfM is a depth learning-driven 3D reconstruction technology aimed at reconstructing the camera pose and 3D structure of a scene from a set of unconstrained 2D images. This technology uses a fully differentiable deep learning framework for end-to-end training. It extracts reliable pixel-level trajectories using depth 2D point tracking technology, while restoring all cameras based on image and trajectory features, and optimizing camera and triangulated 3D points through a differentiable bundle adjustment layer. VGGSfM achieves state-of-the-art performance in three popular datasets: CO3D, IMC Phototourism, and ETH3D.
AI image generation
46.9K
Vastgaussian
VastGaussian is an open-source project for 3D scene reconstruction that leverages 3D Gaussians to model the geometric and appearance information of large-scale scenes. This project is an implementation from scratch and may contain some errors, but it offers a new perspective for the field of 3D scene reconstruction. Key advantages include its ability to process large datasets and the improvements made to the original 3DGS project, enhancing its clarity and usability.
AI 3D tools
49.1K
Fresh Picks
Javavision
JavaVision is a comprehensive visual intelligent recognition project based on Java development. It not only achieves core functions such as PaddleOCR-V4 text recognition, YoloV8 object recognition, face recognition, and image search by image, but also can easily expand to other fields such as voice recognition, animal recognition, and security checks. The features of the project include the use of the SpringBoot framework, multifunctionality, high performance, reliability, easy integration, and flexibility. JavaVision aims to provide Java developers with a comprehensive visual intelligent recognition solution, allowing them to build advanced, reliable, and easily integrated AI applications with the familiar and beloved programming language.
AI image detection and recognition
60.4K
Finecontrolnet
FineControlNet is an official PyTorch implementation for generating images controlled by spatial-aligned text inputs, such as 2D human poses, and instance-specific text descriptions. It can handle a wide range of spatial inputs from simple line drawings to complex human poses. FineControlNet ensures natural interaction and visual coherence between instances and the environment, while retaining the high quality and generalization capabilities of Stable Diffusion, but with enhanced control.
AI image generation
68.4K
ODIN Model
ODIN (Omni-Dimensional INstance segmentation) is a model that uses a transformer architecture for segmentation and labeling on both 2D RGB images and 3D point clouds. It distinguishes 2D and 3D feature operations by iteratively fusing information between 2D views and 3D views. ODIN achieves state-of-the-art performance on ScanNet200, Matterport3D, and AI2THOR 3D instance segmentation benchmarks, and achieves competitive performance on ScanNet, S3DIS, and COCO. When using sampled point clouds from 3D meshes instead of perceived 3D point clouds, it surpasses all previous works. As the 3D perception engine in a guided concretization agent architecture, it sets a new state-of-the-art on the TEACh dialogue action benchmark. Our code and checkpoints can be found on the project website.
AI Model
46.1K
Roboflow
Roboflow is a comprehensive platform for building and deploying computer vision models. Used by over 250,000 engineers, it enables the creation of datasets, model training, and deployment to production environments. With Roboflow, you can train a working, state-of-the-art computer vision model in under 24 hours using just a few dozen example images. It provides a suite of functionalities including dataset management, annotation tools, model training, model deployment, and supports integration with various environments and tools.
Development & Tools
49.7K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
45.5K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
43.3K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
44.2K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
43.6K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
43.6K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.7K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M